

Midjourney
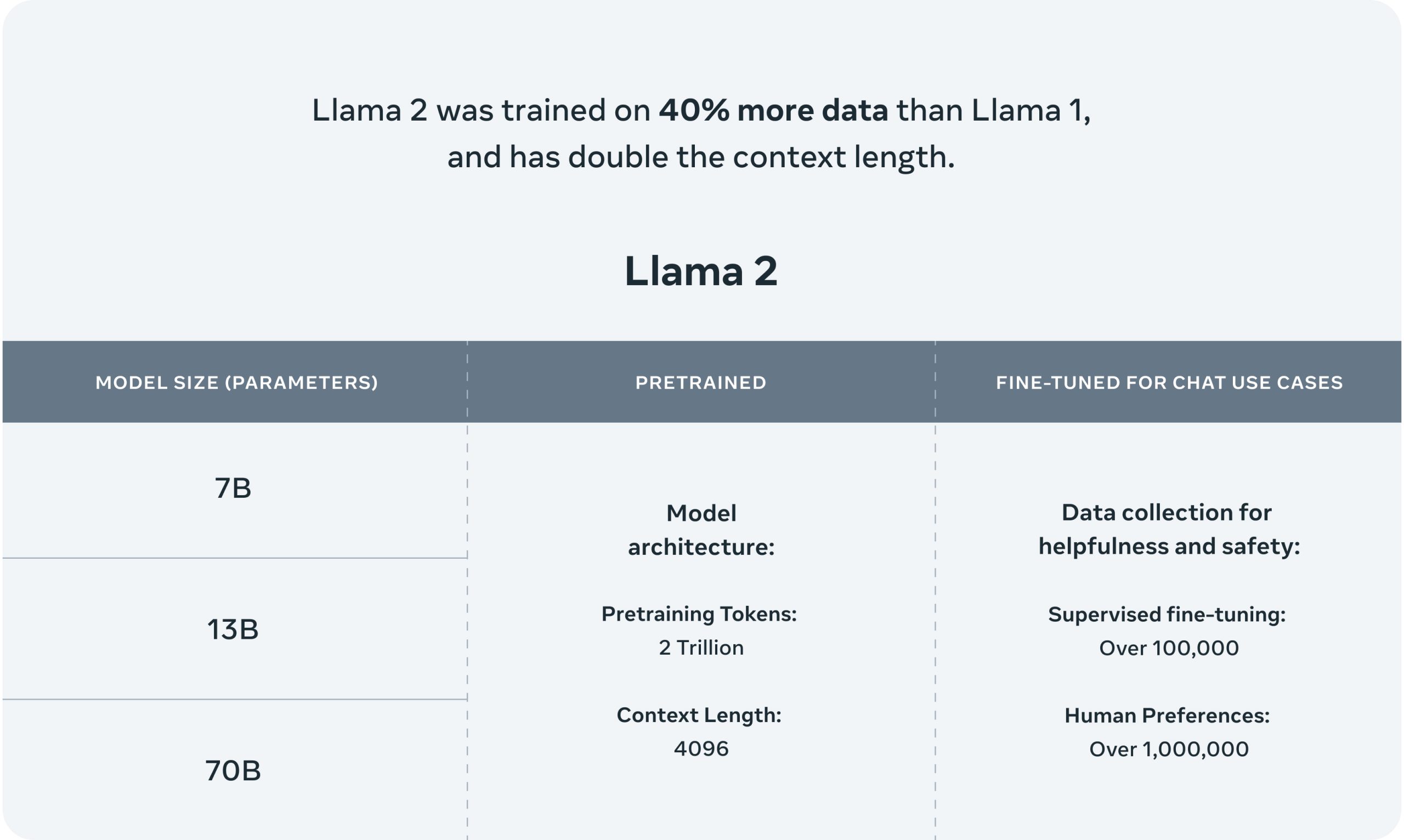
On Tuesday, Meta announced Llama 2, a new open source family of AI language models notable for its commercial license, which means the models can be integrated into commercial products, unlike its predecessor. They range in size from 7 to 70 billion parameters and reportedly “outperform open source chat models on most benchmarks we tested,” according to Meta.
“This is going to change the landscape of the LLM market,” tweeted Chief AI Scientist Yann LeCun. “Llama-v2 is available on Microsoft Azure and will be available on AWS, Hugging Face, and other providers.”
According to Meta, its Llama 2 “pretrained” models (the bare-bones models) are trained on 2 trillion tokens and have a context window of 4,096 tokens (fragments of words). The context window determines the length of the content the model can process at once. Meta also says that the Llama 2 fine-tuned models, developed for chat applications similar to ChatGPT, have been trained on “over 1 million human annotations.”
While it can’t match OpenAI’s GPT-4 in performance, Llama 2 apparently fares well for an open source model. According to Jim Fan, senior AI scientist at Nvidia, “70B is close to GPT-3.5 on reasoning tasks, but there is a significant gap on coding benchmarks. It’s on par or better than PaLM-540B on most benchmarks, but still far behind GPT-4 and PaLM-2-L.” More details on Llama 2’s performance, benchmarks, and construction can be found in a research paper released by Meta on Tuesday.
Meta
In February, Meta released the precursor of Llama 2, LLaMA, as open source with a non-commercial license. Officially only available to academics with certain credentials, someone soon leaked LLaMA’s weights (files containing the parameter values of the trained neural networks) to torrent sites, and they spread widely in the AI community. Soon, fine-tuned variations of LLaMA, such as Alpaca, sprang up, providing the seed of a fast-growing underground LLM development scene.
Llama 2 brings this activity more fully out into the open with its allowance for commercial use, although potential licensees with “greater than 700 million monthly active users in the preceding calendar month” must request special permission from Meta to use it, potentially precluding its free use by giants the size of Amazon or Google.
The power and peril of open source AI
While open source AI models have proven popular with hobbyists and people seeking uncensored chatbots, they have also proven controversial. Meta is notable for standing alone among the tech giants in supporting major open source foundation models, while those in the closed-source corner include OpenAI, Microsoft, and Google.
Critics say that open source AI models carry potential risks, such as misuse in synthetic biology or in generating spam or disinformation. It’s easy to imagine Llama 2 filling some of these roles, although such uses violate Meta’s terms of service. Currently, if someone performs restricted acts with OpenAI’s ChatGPT API, access can be revoked. But with open source software, once the weights are released, there is no taking them back.
However, proponents of open source AI often argue that open source AI models encourage transparency (in terms of the training data used to make them), foster economic competition (not limiting the technology to giant companies), encourage free speech (no censorship), and democratize access to AI (without paywall restrictions).
Perhaps getting ahead of potential criticism for its open source release, Meta also published a short “Statement of Support for Meta’s Open Approach to Today’s AI” that reads, “We support an open innovation approach to AI. Responsible and open innovation gives us all a stake in the AI development process, bringing visibility, scrutiny and trust to these technologies. Opening today’s Llama models will let everyone benefit from this technology.”
As of Tuesday afternoon, the statement has been signed by a list of executives and educators such as Drew Houston (CEO of Dropbox), Matt Bornstein (Partner at Andreessen Horowitz), Julien Chaumond (CTO of Hugging Face), Lex Fridman (research scientist at MIT), and Paul Graham (Founding Partner of Y Combinator).
Although Llama 2 is open source, Meta did not disclose the source of the training data used in creating the Llama 2 models, which Mozilla Senior Fellow of Trustworthy AI Abeba Birhane pointed out on Twitter. Lack of training data transparency is still a sticking point for some LLM critics because the training data that teaches these LLMs what they “know” often comes from an unauthorized scrape of the Internet with little regard for privacy or commercial impact. Meta says it “made an effort to remove data from certain sites known to contain a high volume of personal information about private individuals” in the Llama 2 research paper, but it did not list what those sites are.
Currently, anyone can request access to download Llama 2 by filling out a form on Meta’s website. Ars Technica submitted a request for the download and received a download link about an hour later, suggesting that the list may be manually screened.



")
")





{kind=link}
{kind=link}