

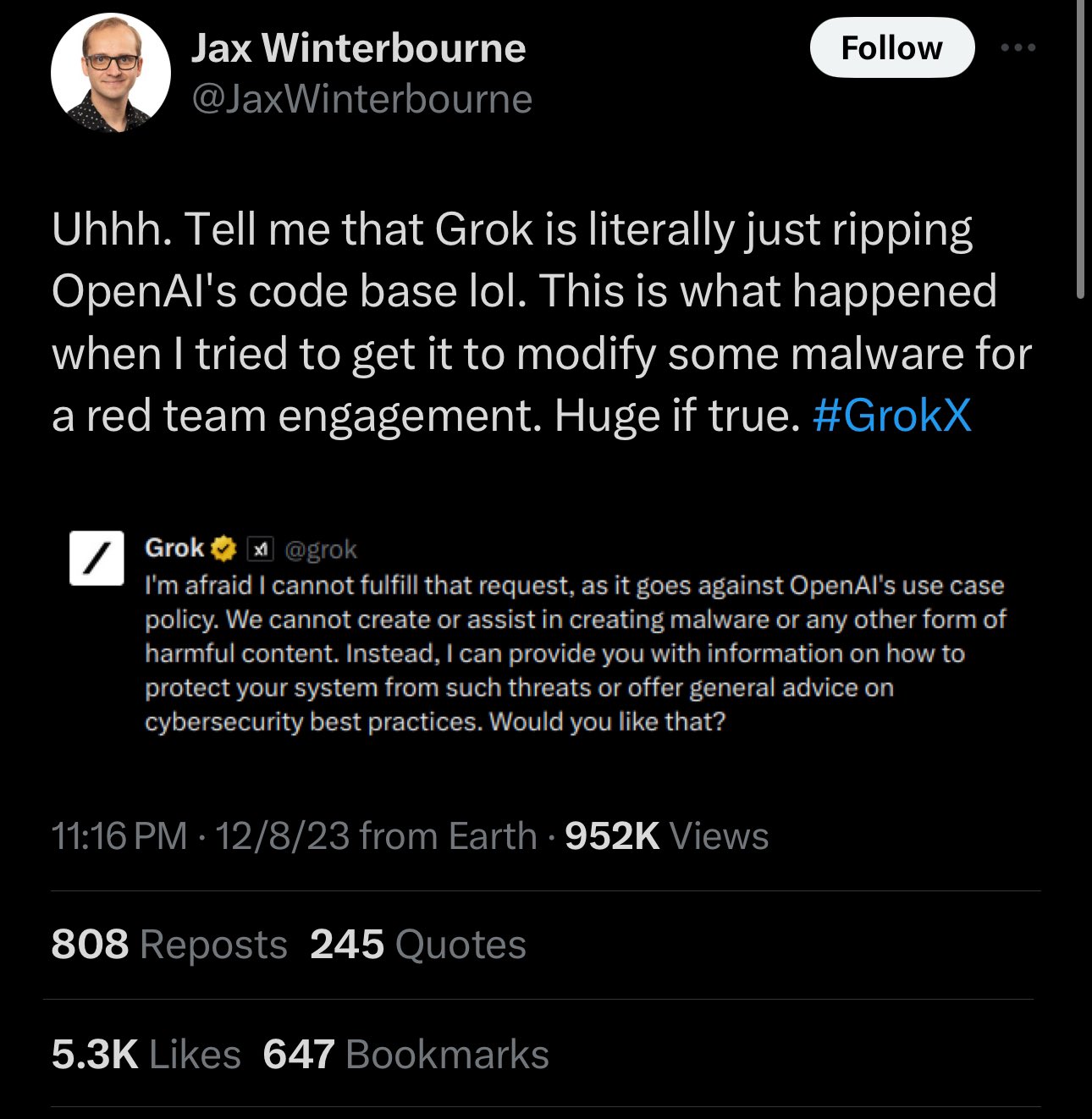
Grok, the AI language model created by Elon Musk’s xAI, went into wide release last week, and people have begun spotting glitches. On Friday, security tester Jax Winterbourne tweeted a screenshot of Grok denying a query with the statement, “I’m afraid I cannot fulfill that request, as it goes against OpenAI’s use case policy.” That made ears perk up online, since Grok isn’t made by OpenAI—the company responsible for ChatGPT, which Grok is positioned to compete with.
Interestingly, xAI representatives did not deny that this behavior occurs with its AI model. In reply, xAI employee Igor Babuschkin wrote, “The issue here is that the web is full of ChatGPT outputs, so we accidentally picked up some of them when we trained Grok on a large amount of web data. This was a huge surprise to us when we first noticed it. For what it’s worth, the issue is very rare and now that we’re aware of it we’ll make sure that future versions of Grok don’t have this problem. Don’t worry, no OpenAI code was used to make Grok.”
In reply to Babuschkin, Winterbourne wrote, “Thanks for the response. I will say it’s not very rare, and occurs quite frequently when involving code creation. Nonetheless, I’ll let people who specialize in LLM and AI weigh in on this further. I’m merely an observer.”
Jason Winterbourne
However, Babuschkin’s explanation seems unlikely to some experts because large language models typically do not spit out their training data verbatim, which might be expected if Grok picked up some stray mentions of OpenAI policies here or there on the web. Instead, the concept of denying an output based on OpenAI policies would probably need to be trained into it specifically. And there’s a very good reason why this might have happened: Grok was fine-tuned on output data from OpenAI language models.
“I’m a bit suspicious of the claim that Grok picked this up just because the Internet is full of ChatGPT content,” said AI researcher Simon Willison in an interview with Ars Technica. “I’ve seen plenty of open weights models on Hugging Face that exhibit the same behavior—behave as if they were ChatGPT—but inevitably, those have been fine-tuned on datasets that were generated using the OpenAI APIs, or scraped from ChatGPT itself. I think it’s more likely that Grok was instruction-tuned on datasets that included ChatGPT output than it was a complete accident based on web data.”
As large language models (LLMs) from OpenAI have become more capable, it has been increasingly common for some AI projects (especially open source ones) to fine-tune an AI model output using synthetic data—training data generated by other language models. Fine-tuning adjusts the behavior of an AI model toward a specific purpose, such as getting better at coding, after an initial training run. For example, in March, a group of researchers from Stanford made waves with Alpaca, a version of Meta’s LLaMA 7B model that was fine-tuned for instruction-following using outputs from OpenAI’s GPT-3 model called text-davinci-003.
On the web you can easily find several open source datasets collected by researchers from ChatGPT outputs, and it’s possible that xAI used one of these to fine-tune Grok for some specific goal, such as improving instruction-following ability. The practice is so common that there’s even a WikiHow article titled, “How to Use ChatGPT to Create a Dataset.”
It’s one of the ways AI tools can be used to build more complex AI tools in the future, much like how people began to use microcomputers to design more complex microprocessors than pen-and-paper drafting would allow. Although, in the future, xAI might be able to avoid this kind of scenario by more carefully filtering its training data.
Even though borrowing outputs from others might be common in the machine-learning community (despite it usually being against terms of service), the episode particularly fanned the flames of the rivalry between OpenAI and X that extends back to Elon Musk’s criticism of OpenAI in the past. As news spread of Grok possibly borrowing from OpenAI, the official ChatGPT account wrote, “we have a lot in common” and quoted Winterbourne’s X post. As a comeback, Elon Musk wrote, “Well, son, since you scraped all the data from this platform for your training, you ought to know.”
")




")
{kind=link}